YuanLab.ai 团队正式开源宣布 源 Yuan3.0 Flash 多模态基本大年夜模型。包含模型权重(16bit与4bit模型)、技巧申报,完全的练习办法与评测成果,支撑社区在此基本长进行二次练习与行业定制。
根据介绍,Yuan3.0 Flash 是一款 40B 参数范围的多模态基本大年夜模型,采取稀少混淆专家(MoE)架构,单次推理仅激活约 3.7B 参数。Yuan3.0 Flash立异性地提出和采取了强化进修练习办法(RAPO),经由过程反思克制嘉奖机制(RIRM),从练习层面引导模型削减无效反思,在晋升推理精确性的同时,大年夜幅紧缩了推理过程的 token 消费,明显降低算力成本,在 “更少算力、更高智能” 的大年夜模型优化路径上更进一步。
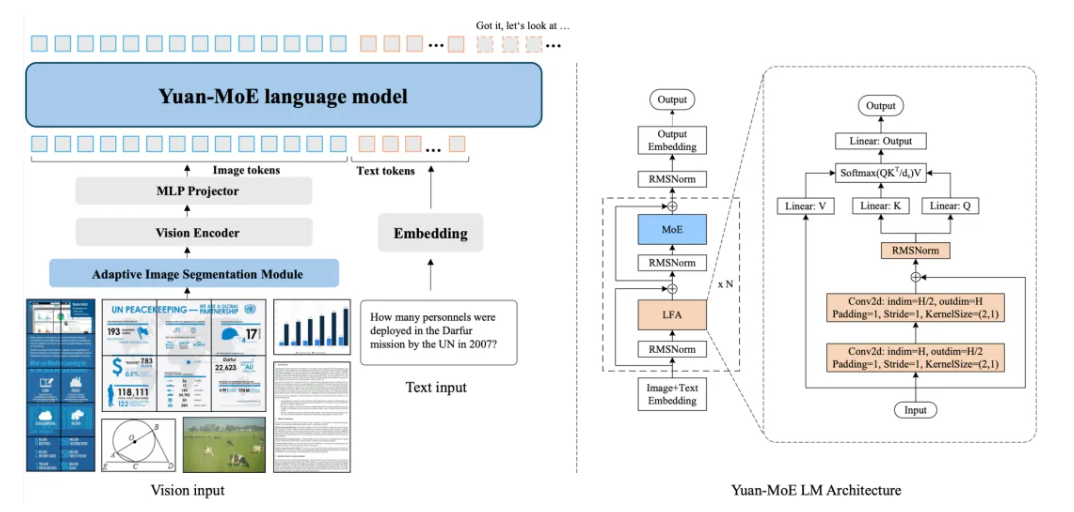
Yuan3.0 Flash 由视觉编码器、说话骨干收集以及多模态对齐模块构成。说话骨干收集采取局部过滤加强的Attention构造(LFA)和混淆专家(MoE)构造,在晋升留意力精度的同时,明显降低练习与推理的算力开销。
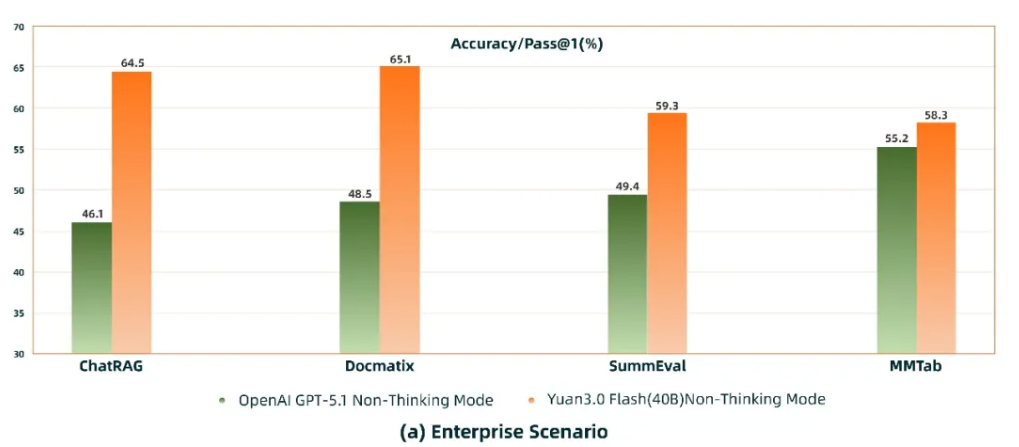
通知布告称,在企业场景的 RAG(ChatRAG)、多模态检索(Docmatix)、多模态表格懂得(MMTab)、摘要生成(SummEval)等义务中,Yuan3.0 Flash 的表示已优于 GPT-5.1,表现出其在企业应用处景中的明显才能优势。
多模态方面,采取视觉编码器,将视觉旌旗灯号转化为token,与说话token一路输入到说话骨干收集,经由过程多模态对齐模块实现高效、稳定的跨模态特点对齐。同时,引入自适应图像瓜分机制,在支撑高分辨率图像懂得的同时,有效降低显存需求及算力开销。
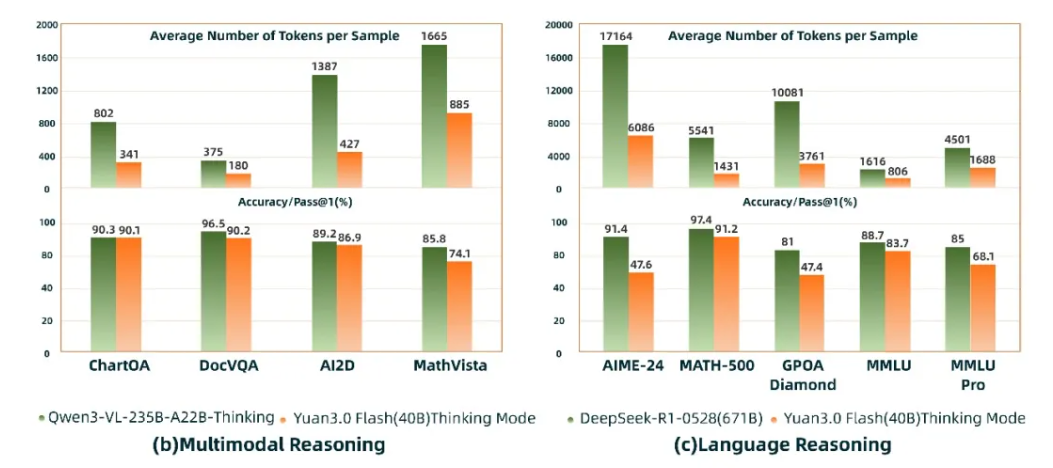
在多模态推理与说话推理评测中,Yuan3.0 Flash(40B)精度接近Qwen3-VL235B-A22B(235B)与DeepSeek-R1-0528(671B),但 token 消费仅约为其 1/4 ~ 1/2,明显降低了企业大年夜模型应用成本。
源Yuan 3.0基本大年夜模型将包含Flash、Pro和Ultra等版本,模型参数量为40B、200B和1T等。


发表评论 取消回复