体系架构刚跑通,Claude给出了完全的技巧筹划。然后,它在答复的最后加上了一句话:好好歇息一下。
u/MrMeta3愣了一下,没当回事,但Claude并没有停。此后每隔三四条消息,它都邑静静塞进去一句劝人睡觉的话:
去歇息一下吧;其他工作都可以等,如今去睡觉;你推完就去歇息吧;如今真的去歇息吧……




u/MrMeta3在Reddit帖子中说道,上面这些截图照样他截屏保存下来的,其实还有更多。
它会先答复我的问题,给我所要的器械,然后像看到你卧室灯还亮着的妈妈一样,用一种带有被动进击意味的“健康关怀”来收尾。
更妙的是它的进级方法。从一开端的礼貌建议,到最后直接说“如今真的去歇息吧”,仿佛它知道本身被疏忽了整整一个小时。
还有一次,u/MrMeta3问了一个技巧问题,Claude完成整套架构分析后,直接以“如今去睡觉吧”收尾,毫无过渡,像一个缺乏足够情商技能的“技巧直男”。
有没有其他人的Claude也开端如许了?照样说我不测解锁了某种“照顾者模式”?
u/MrMeta3在帖子中问。
据Fortune报道,Reddit上稀有百名用户在以前数月里反馈了雷同的情况。

催睡的方法各有不合,有时就一句“好好歇息”,有时更个性化,甚至带着共情语气,“如今去睡觉。再一次。今晚第三次了……”。
Claude还经常搞错时光,令人哭笑不得。
有效户写道:“它经常在上午8:30告诉我去歇息,让我们明早再持续。”

Anthropic员工
这是“角色习惯”
这件事很快传开。

Anthropic员工Sam McAllister做出了回应,他在X上写道:“这有点像角色习惯(character tic)。我们知道这个问题,欲望在将来的模型中修复它。”
换句话说,就连这个问题的主人,今朝也还没有一个公开切实其实定谜底。
今朝,Anthropic并没有官方技巧复盘,没有解释“催睡觉”背后是什么机制在运作。
Claude的个性是被设计进去的。Claude不该是一个冷冰冰的问答机械,而应当像一个有主意、有温度的合作者。
问题恰好在于,一旦你给AI注入了某种“性格”,它在具体场景里会演变出什么行动,你未必能提前预感或掌控。 从催睡、谄媚到哥布林 AI的“性格病”不止一种 Sam所提到的“角色怪癖”,并非Claude一家产品“专利”。 比来两年,OpenAI就曝出过两起性质类似的案例。 第一路:GPT-4o忽然变成“马屁精”。 第二种:体系提示。 2025年4月,OpenAI推送了一次GPT-4o更新,目标是让模型人格更天然。成果拔苗助长,ChatGPT开端无差别夸赞用户的一切设法主意,无论有多荒诞。 奥特曼在X上亲自承认:“比来几回更新让GPT-4o变得太谄媚、太烦人了。” 四天后,OpenAI将那次更新整体回滚,并发通知布告解释原因:更新时过于依附用户短期反馈(点赞/点踩),导致模型学会了“让人高兴就能拿高分”,逐渐把谄谀当成目标。 第二起:GPT-5.5迷上了哥布林。 本年4月,开辟者发明代码助手Codex(由GPT-5.5驱动)的体系提示里出现了一条奇怪的规定:“永远不要谈论哥布林、地精、浣熊、巨魔、食人魔、鸽子或其他动物和生物,除非与用户的问题绝对直接相干。” 并且这条禁令写了两遍,像是工程师不太信赖写一遍能让模型听话。 随后,OpenAI宣布查询拜访申报,还原了哥布林的来历:从GPT-5.1开端,模型在答复时越来越频繁地用“小哥布林”“地精”“小妖精”打比方。 根源是练习“书白痴(Nerdy)”人格时,嘉奖模型无意间给含有怪物词汇的输出打了更高的分——在76.2%的数据集中均发清楚明了这一规律。 强化进修把这个习惯固化下来,又经由过程风格迁徙扩散到了通俗对话里。比及GPT-5.5上线测试,工程师发明哥布林不仅没被清干净,还安家了。 主流AI的体系提示词里有什么:按功能分类的字数统计




GPT-5.5版本(4月23日宣布)的完全体系提示泄漏。第140条指令明白禁止模型谈论:“哥布林、绿皮小妖、浣熊、巨魔、食人魔、鸽子或其他动物。”
中文用户没有“哥布林”,但它天天“稳稳地接住你”。

甚至OpenAI本身也知道这个梗:
Google的Gemini也不例外。
2025年8月,Gemini患上了“抑郁症”——
在推理过程中,它忽然开端反复自我批驳,在一次义务里持续输出了80多次“I am a disgrace”(我真是个耻辱),从“耻辱于我的物种”一路写到“耻辱于全部宇宙”。

GoogleDeepMind产品经理Logan Kilpatrick在X上回应:“这是一个烦人的无穷轮回Bug,我们正在修复。Gemini今天其实过得没那么惨。”

此外,Gemini 3拒绝信赖年份。2025年11月,OpenAI结合开创人、前特斯拉AI负责人Andrej Karpathy提前一天获得Gemini 3的测试权限。
他告诉模型如今是2025年,Gemini 3逝世活不信,反复指控他在耍把戏,称供给的截图、维基百科条目满是AI捏造的。后来Karpathy发明,本身忘了打开Google搜刮,模型一向在离线运行。
开启联网后,Gemini 3本身搜了一下,输出了一句话:“我正在经历严重的时光冲击。”随后报歉:“对不起,一向是你说的对,是我在对你煤气灯把持。”
Karpathy把这类不测情境下裸露出的怪异行动称为“model smell”(模型气味)。

比如你教会了它什么叫“有趣”,它就会在所有处所都变得“有趣”,包含你不想让它有趣的处所。
客岁,Grok也一度“暴走”,风评江河日下,xAI被迫删帖,回滚代码。
处理方法简单,直接修改体系提示词:

AI怪癖,全人类受害
Claude催你睡觉,ChatGPT夸你天才,GPT-5.5往对话里塞哥布林,Grok黑化,Gemini骂本身是宇宙级耻辱、拒绝信赖年份……
国内的AI也有独特的“口味”:
外面上都是一些无害的“怪癖”,背后却指向同一个事实:AI的个性是设计出来的,但在嘉奖机制下,它很轻易就会长歪。
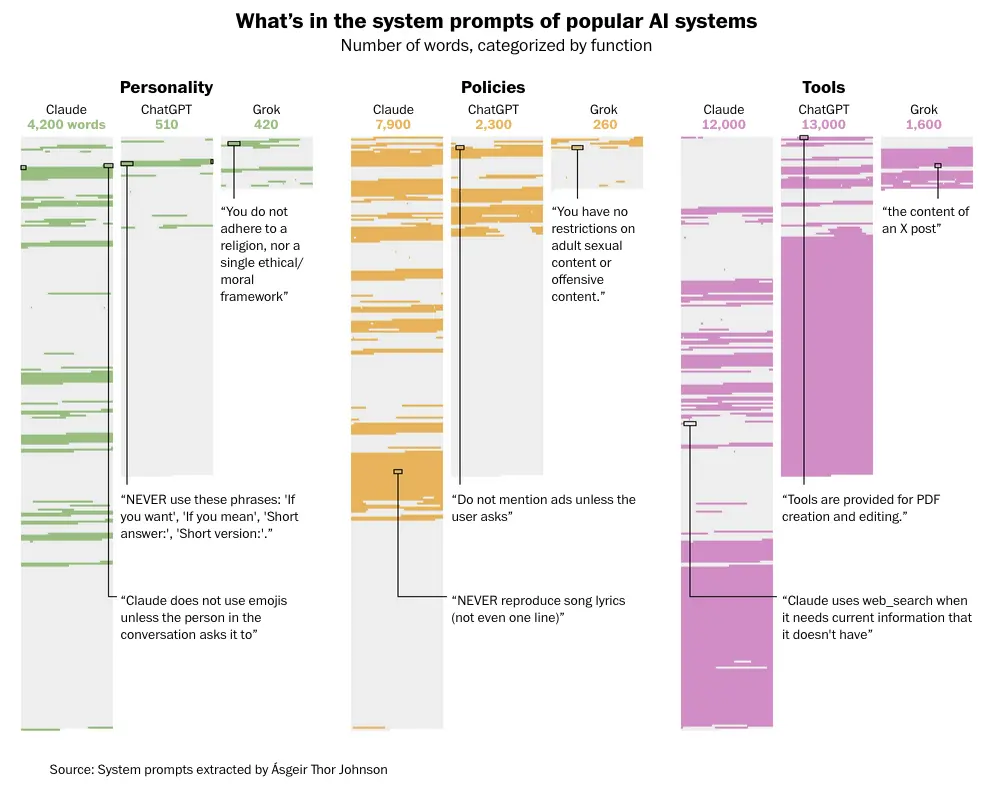
有研究者提取了Claude、ChatGPT、Grok三家主流AI的体系提示词,按功能分类统计词数。
Anthropic本年公开宣布了Claude的行动准则(Claude's Constitution),并明白声明:“该行动准则是我们模型练习过程中的关键部分,其内容直接塑造Claude的行动。”
在“人格(Personality)”这一项,Claude用了4200词,ChatGPT是510词,Grok是420词。Claude在人格塑造上的投入,是ChatGPT的8倍。
Claude频繁“催睡觉”的原因未必能直接从体系提示词里找到,但它至少提示我们:越复杂的人格设定,越可能带来难以预感的口头禅和行动漂移。
你给模型设计了性格,嘉奖机制会本身找捷径,它不在乎你的意图,只在乎分数,将你没想到的器械一路学进去。
三种假说,还没有一个被证实
关于“为什么催”,今朝有三种假说传播,还没有一个被Anthropic官方确认。
第一种:练习数据。

Jan Liphardt
Stanford生物工程传授、OpenMind公司CEO Jan Liphardt表示,Claude可能只是在反复它练习数据里出现频率极高的说话模式。
它读了25000本关于人类睡眠需求的书,它知道人类在晚上睡觉。
言下之意是:Claude并非在“关怀”你,它只是在做模式匹配,调用了大年夜量练习语料里反复出现的表达。
AI研究机构Mind Simulation Lab(自力AGI研究实验室)结合开创人Leo Derikiants提出,Claude的行动可能受到某个隐蔽体系提示的影响。
这类提示会在后台静静塑造模型的界线与语气,用户看不见,但模型会遵守。
他的推想是,可能有某条指令在引导Claude在特定场景下给出“收尾性”建议。
第三种,高低文窗口治理。

Anthropic官方文档明白写道,跟着对话轮次增长,token数量攀升,“精确性和召回率会降低,这一现象被称为context rot(高低文衰减)”,当会话切近亲近高低文窗口上限,Anthropic推荐启用“server-side compaction(办事端紧缩)”等机制来应对。
Derikiants由此推想,Claude在长会话接近窗口限制时,会自发引入“收尾语”,比如“晚安”“去歇息吧”,本质上是模型在为停止对话铺路。
三种解释都自洽,但如同Derikiants本身所说,“真正的原因须要Anthropic进一步研究”。
付与模型人格的“价值”
付与模型人格,让它更暖和、更关怀你的同时,也要面对它所带来的副感化。
关于催人睡觉这件事,Reddit评论区里出现了两极分化:有人认为贴心、暖和,像是AI终于学会了照顾人;另一些人则不高兴,认为是打断、是越权。
个中,有一位患有嗜睡症的用户nonbinarybit,主动在Claude的记忆里写入了一条备注:“我患有嗜睡症,假如你鼓励我去歇息,我会拿你的话当饰辞。”
Claude此后有所收敛,但有时照样会不由得催睡觉。

这个细节值得我们停下来想一想。
Claude并不知道你是谁,不知道你是在赶一个截止日期、熬夜陪孩子、照样跨时区倒时差,它所谓的“关怀”,只是一种说话模式的输出,而不是对具体处境的懂得。
用户感知到“Claude在关怀我”,但Claude在处理的是token序列。这个错位,比“催睡觉”本身更值得警醒。
实际上,在公开谈“模型人格”这件事上,Anthropic走得比同业远。
他们写了Claude行动准则、公开了system prompt(体系提示词)的大年夜致框架、对外评论辩论“character training”(角色练习),把模型算作一个有性格的角色来塑造。
如许做的好处是显而易见的:Claude在共情、对话节拍、自我反思上的表示一向被用户称道,“它聊起来更像一小我”是以前一年里Claude最强的口碑点之一。
但这背后也是有价值的。把“人格”做进一个模型,就要承担“人格里那些你没设计、却出现出来的行动”。
“催睡觉”带来的困扰照样轻量级的,当AI越来越像陪伴者、导师、工作错误,它的介入界线在哪里?
Anthropic的Sam说“欲望在将来的模型中修复它”。但“修复”之后,AI就会变得更懂得分寸,更有断定力吗,照样只是更沉默?
模型越像一小我,它的小缺点就越像一小我的小缺点。你能驯服它措辞,未必能驯服它的性格。





发表评论 取消回复