
4月24日,全球最大年夜AI模型应用法度榜样编程接口聚合平台OpenRouter的数据显示,V4-Flash的调用量达270亿Token,V4-Pro为47.9亿Token,但没有登上排行榜。
DeepSeek-V4宣布后,主流评测平台进行了才能测试和排名。
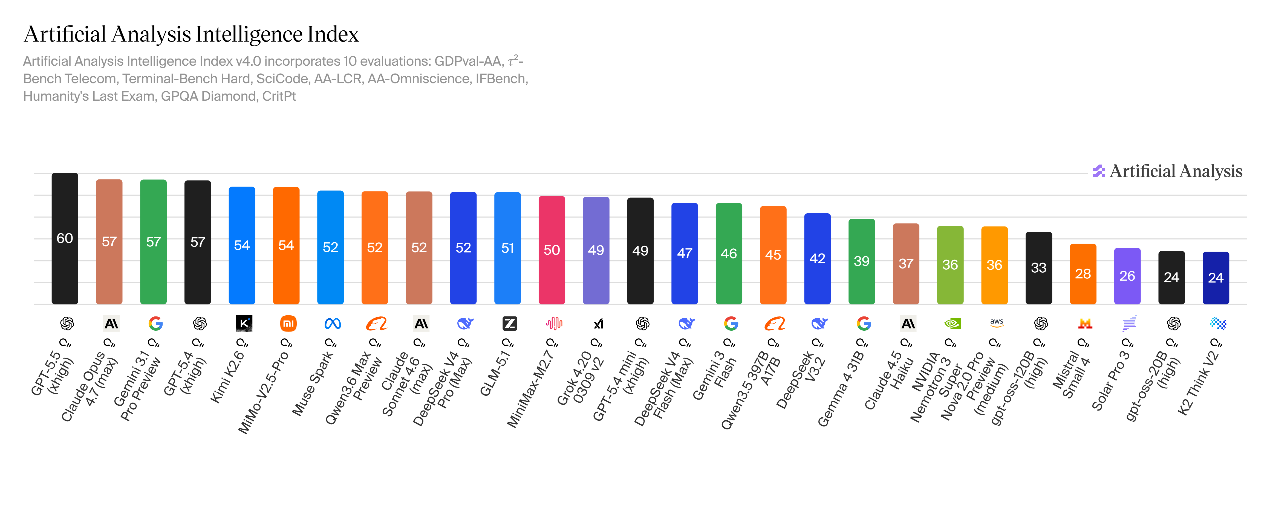
V4-Flash得分47分,机能弱于V4-Pro,但明显超出DeepSeek-V3.2,综合智能程度对标Claude Sonnet 4.6(全力版),介于顶尖闭源模型与主流中端模型之间。
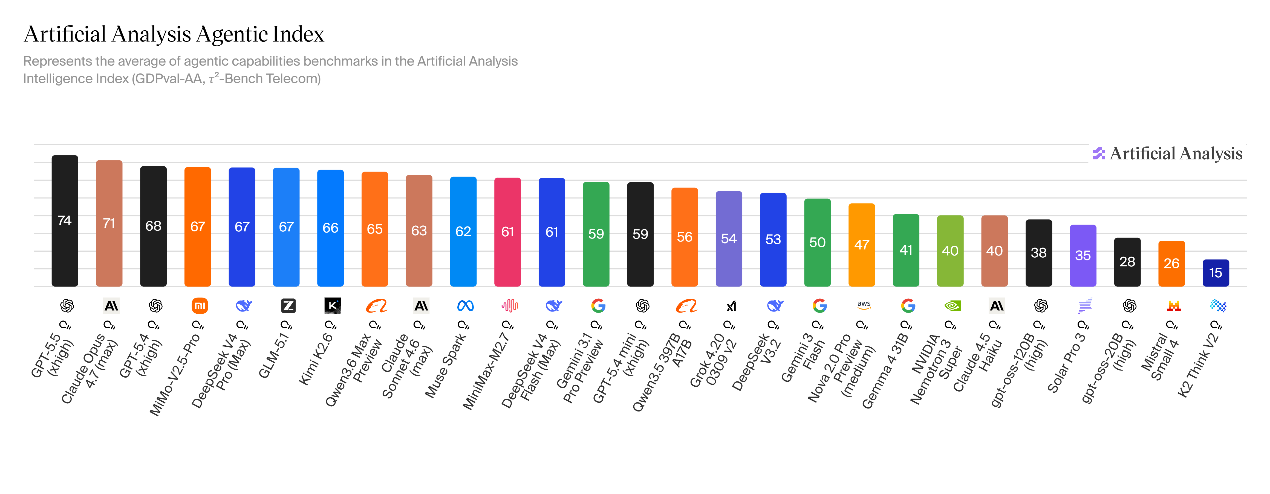
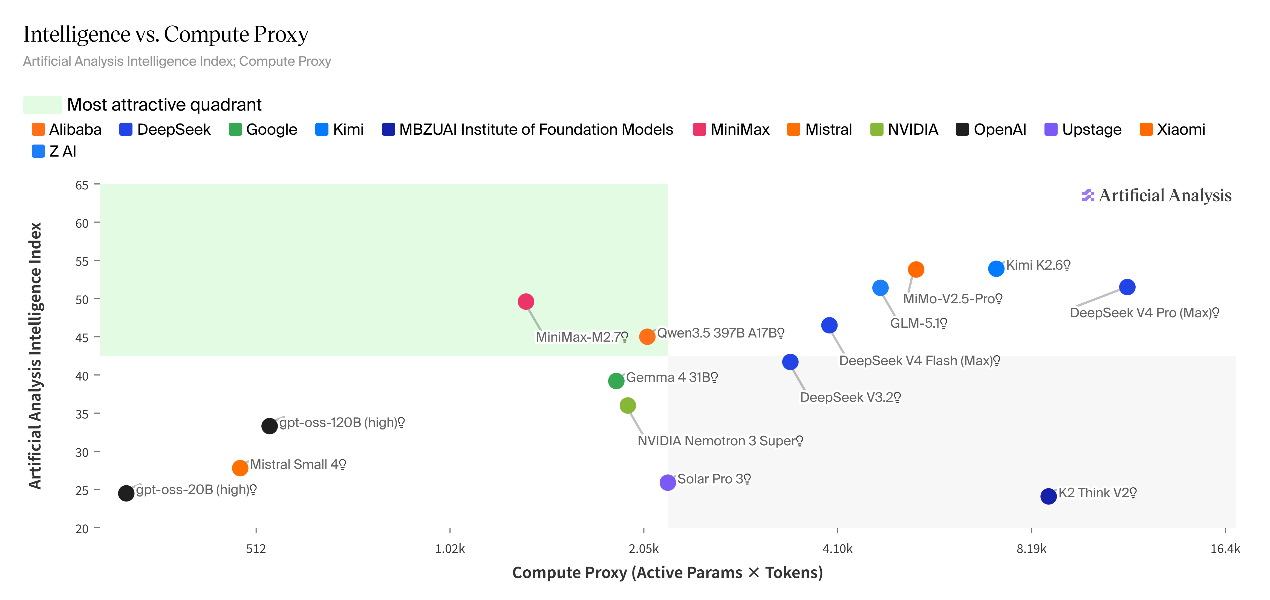
在智能体义务表示方面,V4-Pro在真实场景智能体工作义务中,机能位居所有开源权重模型首位,得分1554,超出Kimi K2.6(1484)、GLM-5.1(1535)、GLM-5(1402)以及MiniMax-M2.7(1514)。
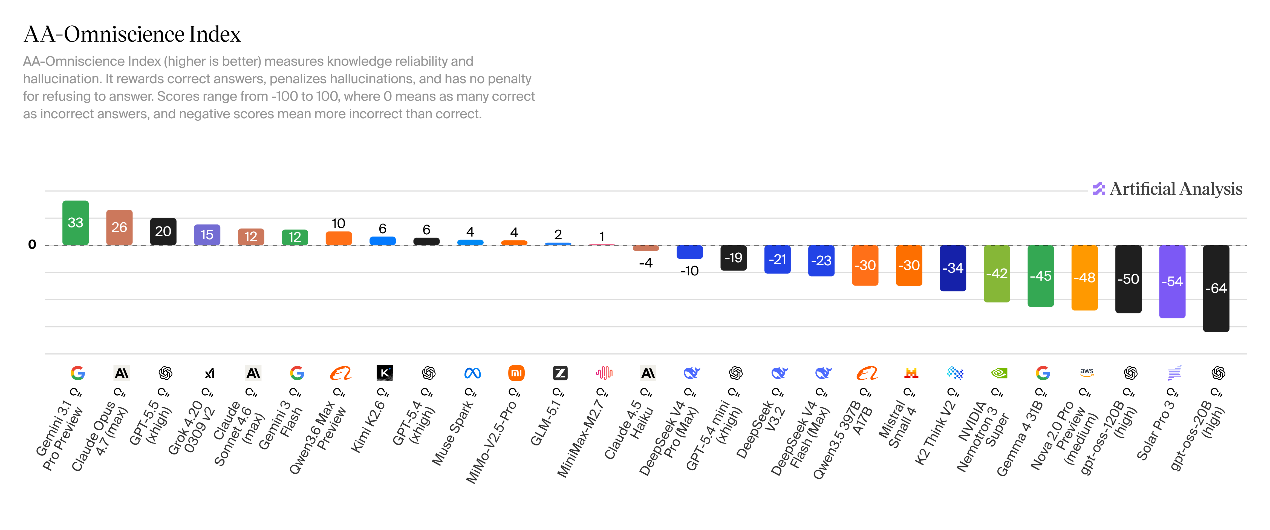
DeepSeek-V4常识贮备进级,但幻觉产生率上升。V4-Pro在全知综合评测指标(AA-Omniscience)中得分为-10,较V3.2推理版晋升11分,核心得益于常识答复精确率的明显优化。V4-Flash得分为-23,整体程度与V3.2根本持平。
DeepSeek-V4的运行成本低于顶级闭源模型,高于主流开源模型,较前代大年夜幅上涨。完成全套人工分析智能指数测评,V4-Pro的运行成本为1071美元,仅不到Claude Opus 4.7(4811 美元)的四分之一;但比较同类开源模型仍偏高,高于Kimi K2.6(948 美元)、GLM-5.1(544美元)、DeepSeek-V3.2(71美元)、gpt-oss-120B(67 美元)。DeepSeek-V4-Flash运行成本仅约113美元,成本优势明显。
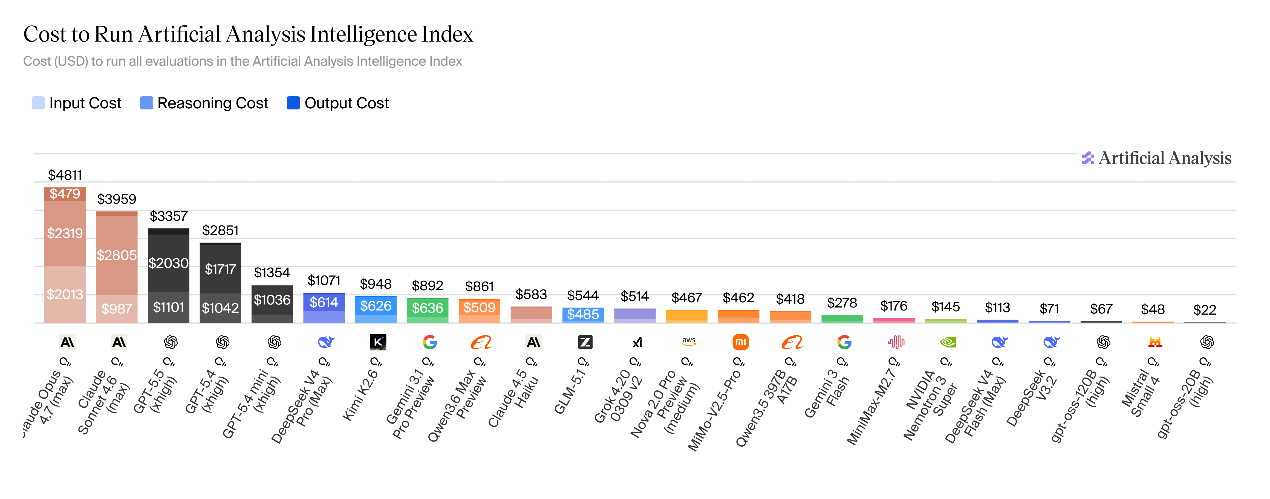
完成标准测评流程,V4-Pro输出Token消费量达1.9亿,属于本次测评中Token消费最高的模型之一;V4-Flash消费进一步攀升至2.4亿Token。即便订价偏低,高额的Token消费仍是V4-Pro综合应用成本高于其他开源模型的核心原因。
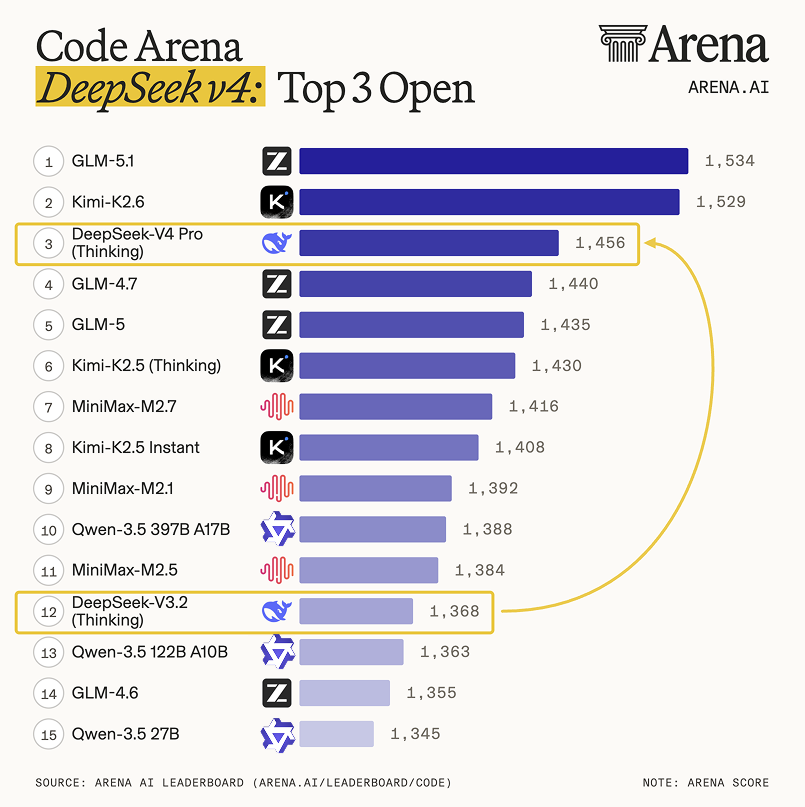
在其他评测中,大年夜模型竞技场Arena.ai将DeepSeek-V4-Pro定性为“相较DeepSeek-V3.2的重大年夜飞跃”,在其代码竞技场中位列开源模型第3位、综合第14位。DeepSeek-V4-Pro在智能体网页开辟义务中与GPT-5.4-high和Gemini-3.1-Pro处于同一程度。在其文本竞技场中,DeepSeek-V4-Pro位列开源模型排名第2、综合第14,与Kimi-2.6持平。DeepSeek-V4-Flash位列开源模型排名第10、综合第14。
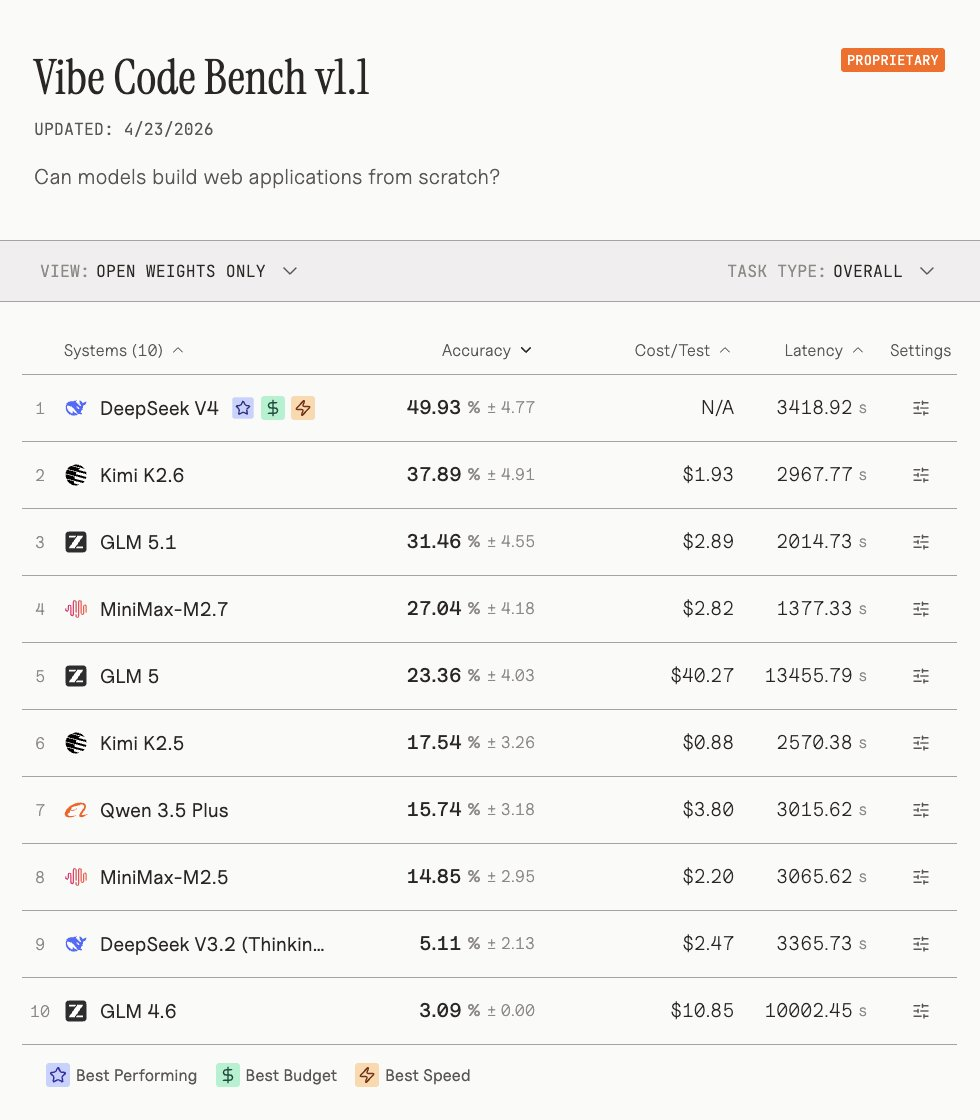
另一家测评方Vals AI称,DeepSeek-V4在其Vibe Code Benchmark(氛围代码基准)中以“胜过性优势”拿下开源权重模型榜首,较上代V3.2实现约10倍机能跃升,甚至击败了像Gemini 3.1 Pro如许的顶尖闭源模型。DeepSeek-V4也是独一一个在Vibe Code Benchmar上冲破40%的开源权重模型。
相较于DeepSeek-V4的才能,海外加倍存眷DeepSeek与华为的合作。
在DeepSeek-V4颁布API价格信息的最下方,官方特别标注指出:“受限于高端算力,今朝Pro的办事吞吐量十分有限,估计下半年昇腾(Ascend)950超节点批量上市后,Pro的价格会大年夜幅下调。”
DeepSeek在技巧申报中称,V4已在NVIDIA GPU和华为昇腾NPUs平台上验证了精细粒度的EP(专家并行)筹划,相较于强大年夜的非融合基线,其在通用推理义务上可实现1.50~1.73倍的加快后果,而在对时延敏感的场景(如RL推演和高速代理办事)中则可达到1.96倍的加快后果。
而在V4宣布后,华为昇腾也同步宣布“超节点全系列产品支撑DeepSeek-V4系列模型”。据悉,昇腾950经由过程融合kernel和多流并行技巧降低Attention计算和访存开销,大年夜幅晋升推理机能,结合多种量化算法,实现了高吞吐、低时延的DeepSeek-V4模型推理安排。
对于DeepSeek此次与华为合作,市场研究机构Omdia半导体研究主管何辉表示:“这对中国人工智能行业而言意义重大年夜。”
他进一步说道:“华为昇腾芯片是中国自研程度最高、可替代英伟达的产品。DeepSeek-V4大年夜模型适配搭载华为芯片,标记住中国顶级大年夜模型如今已可以或许实现国产化硬件落地运行。”
高盛分析师Christopher Moniz点评称,DeepSeek-V4预览版宣布后,GPU及国产芯片板块回声走强。核心存眷点之一是支撑V4模型的芯片底层架构:包含模型练习所应用的芯片,以及推理阶段搭载的硬件设备。华为搭载昇腾AI处理器的新一代人工智能计算集群,可适配运行DeepSeek-V4模型。这也意味着,中国自研AI硬件生态,正在为DeepSeek持续迭代前沿大年夜模型供给算力支撑。
DeepSeek此次技巧路线转向,也印证了英伟达首席履行官黄仁勋此前的担心:英伟达正面对掉去中国开辟者生态的风险。
本月上旬,英伟达开创人黄仁勋在接收Dwarkesh Patel专访时曾言:“假如DeepSeek先在华为平台上宣布,那对美国来说将是灾害性的。”在黄仁勋看来,固然DeepSeek是一款开源模型,同样可被用于英伟达产品上,但假如DeepSeek专门针对华为算力进行优化,在高端算力采购受限等局限下,英伟达将处于劣势。
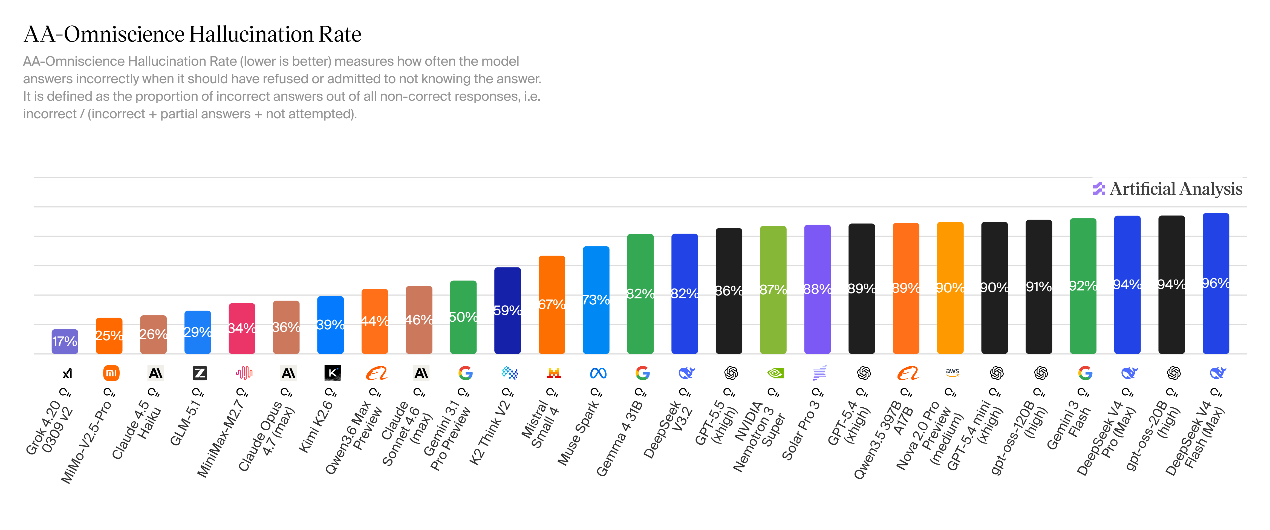
相较于V3.2的幻觉率(82%),V4两款模型的幻觉问题凸起:V4-Pro幻觉率为94%、V4-Flash幻觉率为96%,意味着模型在未知问题场景下,几乎都邑强行生成谜底。
与DeepSeek-R1不合,DeepSeek-V4并没有激发美国科技股大年夜跌。晨星高等股票分析师Ivan Su表示,DeepSeek-V4很难复刻推理模型R1当初的市场影响力,因为交易市场早已充分消化了预期:中国人工智能技巧具备竞争力,且应用成本更低。
Ivan Su还称,DeepSeek此次全新的产品定位,将国内其他开源大年夜模型直接划入竞操行列。
Artificial Analysis对DeepSeek-V4进行了推理才能专项测评。成果显示,V4-Pro在人工分析智能指数中斩获52分,相较V3.2版本的42分实现10分跃升,成为仅次于Kimi K2.6的全球第二大年夜开源推理模型。
布鲁金斯学会研究员Kyle Chan表示,DeepSeek-V4令人印象深刻,因为它是一个接近最先辈程度的模型,具有高效的100万Token高低文长度,并且可以在华为的新芯片上运行。DeepSeek-V4没有复制“DeepSeek-R1时刻”,因为外界对中国AI才能的期望值要比以往高得多。





发表评论 取消回复